


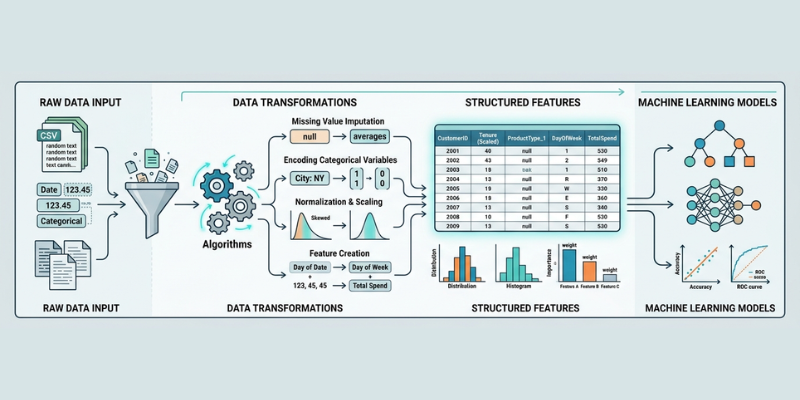
Feature engineering is one of the most important steps in any data science project. It focuses on transforming raw data into meaningful inputs that help machine learning models perform better. Even the most advanced algorithm can fail if the input features are poorly designed. A strong feature set often makes a bigger difference than the choice of model itself.
For beginners, this concept may feel complex at first, but it becomes easier with practice and a clear understanding. Learning how to select, transform, and create useful features can significantly improve prediction accuracy. If you are looking to build a solid foundation, consider enrolling in Data Science Courses in Bangalore at FITA Academy to strengthen your practical skills further.
What is Feature Engineering
Feature engineering involves developing new input variables or altering current ones to enhance the performance of a model. These features represent patterns in data that help algorithms understand relationships more effectively.
It involves tasks like managing missing values, transforming categorical variables into numerical formats, normalizing numerical data, and creating new features from the current columns. Each step aims to make the data more suitable for machine learning algorithms.
Why Feature Engineering Matters
Machine learning models learn from data, not from assumptions. If the data is not well prepared, the model cannot identify useful patterns. Feature engineering ensures that the data highlights meaningful relationships.
Good features can reduce noise and improve accuracy. They also help models converge faster during training. In many real scenarios, improving features delivers better results than tuning algorithms.
Handling Missing Data
Missing values are common in datasets. Ignoring them can lead to incorrect predictions. Feature engineering provides strategies such as filling missing values with mean, median, or mode.
Another approach is to create a new feature that indicates whether data was missing. This can sometimes reveal hidden patterns. Choosing the right method depends on the type of data and problem.
Encoding Categorical Variables
Machine learning models work with numbers, not text. Categorical data must be converted into numerical form. Techniques like label encoding and one-hot encoding are widely used.
Choosing the correct encoding method is important. Poor encoding can mislead the model and reduce accuracy. Understanding these techniques helps you prepare data effectively. If you want hands-on learning, you can explore a Data Science Course in Hyderabad to practice these methods in real projects.
Feature Scaling and Transformation
Different features often have different ranges. Some values may be very large, while others are very small. This can affect model performance, especially for distance based algorithms.
Feature scaling methods, such as normalization and standardization, bring all values to a similar range. Transformations like log scaling can also help reduce skewness in data. These steps improve model stability and accuracy.
Creating New Features
Creating new features from existing data is a powerful technique. For example, combining date fields to extract day, month, or year can provide additional insights.
You can also create interaction features by combining two or more variables. These new features often capture relationships that the model might otherwise miss. Creativity plays a key role in this process.
Feature engineering is both an art and a science. It requires understanding the data, experimenting with transformations, and evaluating results carefully. Strong features can turn a simple model into a highly effective one.
As you continue learning, focus on practicing different techniques and understanding their impact on performance. If you are ready to deepen your knowledge, join a Data Science Course in Ahmedabad to gain practical experience and advance your skills further.
Also check: Probability Theory Basics for Data Science